
Data Center Trends & Cooling Strategies to Watch in 2026
January 5, 2026
AI Is Moving to the Water’s Edge, and It Changes Everything
January 5, 2026AI is accelerating data center growth in ways that traditional compute never did, and by 2030, AI is expected to represent nearly half of all compute workloads. That surge comes from the two sides of the AI lifecycle:
- AI training, which fuels the evolution of ever-smarter, more complex models.
- AI inference, which deploys those models in real-time.
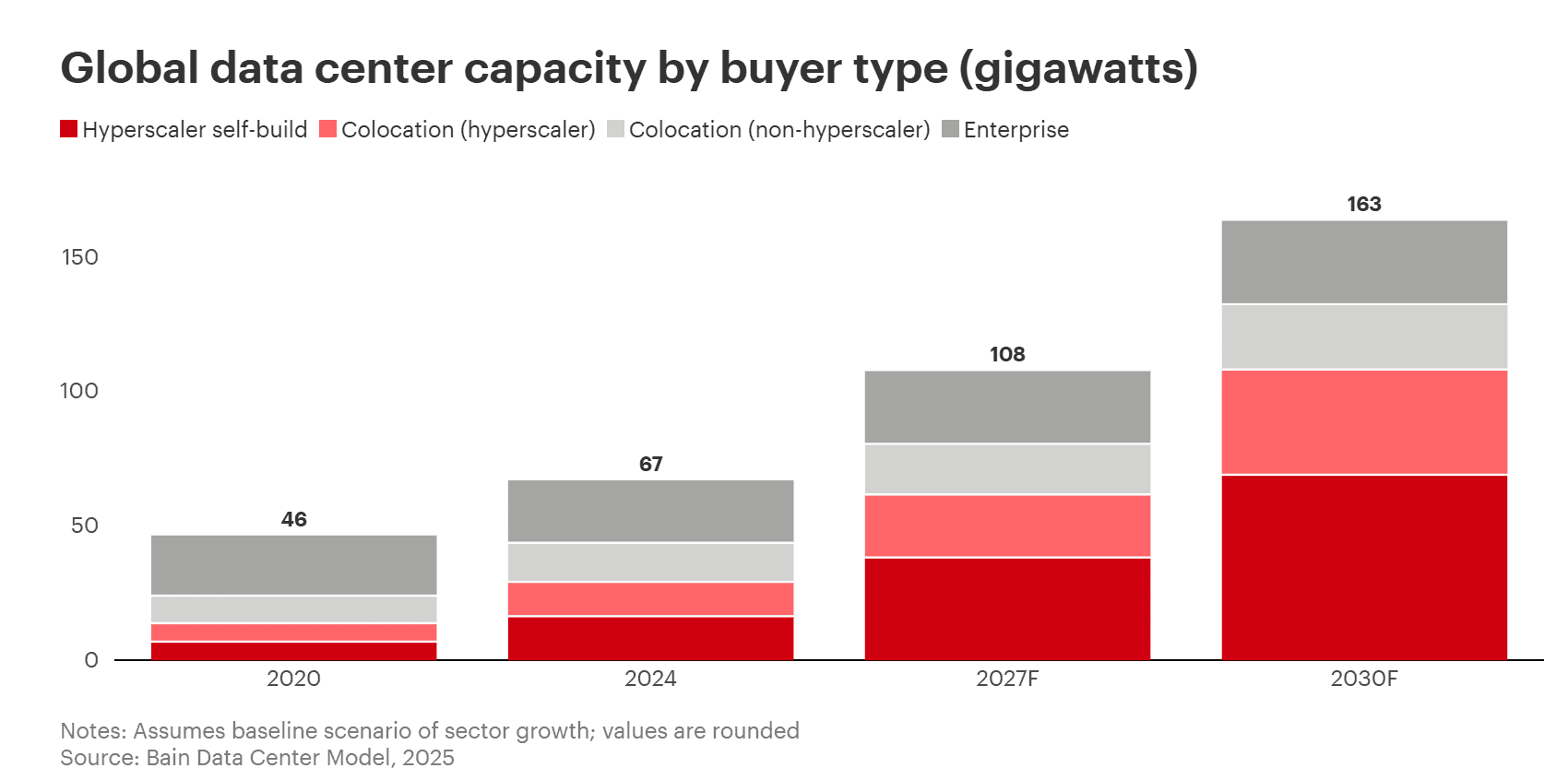
- Inference in particular is set for massive expansion, with Bain & Company projecting inference data center capacity to rise from just 2 gigawatts in 2024 to 54 gigawatts by 2030.
As these two workloads scale, they place distinct demands on the infrastructure that supports them, especially cooling.
This article breaks down the core differences between AI training and AI inference and explains what each means for data center cooling.
What’s the Difference between AI Training and AI Inference?
Before diving into the cooling discussion, it helps to briefly outline the key characteristics and differences between AI training and AI inference in data centers:
| Category | AI Training | AI Inference |
|---|---|---|
| Purpose | Teaches the model patterns from large datasets (builds the model). | Uses the trained model to make predictions or outputs on new data. |
| Compute Intensity | Extremely high; massive parallel compute required. | Moderate to high; depends on model size and concurrency. |
| Workload Pattern | Long-running, predictable processes. | Real-time, bursty, latency-sensitive demand. |
| Frequency of Operation | Episodic (models trained periodically). | Continuous (millions to billions of queries daily). |
| Latency Requirements | Not latency-sensitive; throughput matters more. | Highly latency-sensitive for user experiences. |
| Energy Consumption | Very high; dominated by multi-GPU clusters. | Lower per query but high in aggregate due to constant usage. |
| Deployment Scale | Centralized in large training clusters or hyperscalers. | Highly distributed across edge and local sites. |
| User Impact | Invisible to end users; happens behind the scenes. | Directly influences user-facing AI experiences. |
Cooling Considerations for Training and Inference Workloads
With the differences between AI training and inference clear, we can now look at how each shapes key cooling considerations.
What Cooling Trends Do AI Training and Inference Share?
Despite serving different purposes, AI training and inference share some similar cooling trends:
- Growing Adoption of Liquid Cooling: Both workloads increasingly rely on liquid cooling methods (direct-to-chip, immersion, CDUs) to overcome thermal limits and sustain high GPU performance.
- Thermal Monitoring & Management: Training and inference can benefit from AI-driven thermal monitoring and control systems to maintain safe temperatures and prevent performance degradation.
- Density-Driven Cooling Innovation: As both workloads push hardware toward higher power densities, cooling systems must evolve to remove more heat in less space.
What Are the Cooling Differences between AI Training and Inference?
Beyond their shared foundations, the thermal characteristics of training and inference drive distinctly different cooling approaches that are increasingly shaping how data centers are designed:
Cooling Deployment Environment:
Training workloads are almost always housed in hyperscale or large colocation facilities. These high-density environments demand high-capacity cooling engineered for maximum heat removal, making liquid cooling, and especially CDUs, the ideal fit. CDUs not only deliver the thermal performance required for training clusters but can also be placed closer to the IT load, avoiding the need to route cooling across massive rooms.
Inference, on the other hand, is increasingly deployed in modular, regional, and edge data centers where space, power availability, and environmental conditions vary widely. These settings require compact, adaptable cooling systems that can be deployed quickly and still operate reliably. As a result, cooling strategies for inference must prioritize flexibility and scalability to support fast-growing deployments.
Cooling Demand Patterns:
AI training demands sustained, extremely high cooling intensity to support compute workloads that run for hours, days, or even weeks without interruption. This creates a dense, predictable thermal load that requires cooling systems capable of predictable, efficient cooling over extended periods.
Inference, by contrast, generates heat in short, unpredictable bursts driven by user traffic, model behavior, and real-time application needs. Cooling must therefore respond instantly to these fluctuations, scaling output up or down without introducing latency or affecting response times. So, rather than sustained maximum cooling, inference environments depend on adaptive, variable-capacity cooling systems.
Cooling Uptime Requirements:
Training workloads run behind the scenes in long, controlled cycles, giving operators more flexibility in how cooling uptime is managed. Because these jobs can be checkpointed and resumed, cooling systems can tolerate slightly longer recovery windows without jeopardizing overall progress.
Inference operates in real time, directly supporting user-facing applications where even small disruptions are immediately visible. As a result, cooling uptime requirements are far more stringent, as even brief thermal interruptions can cause latency issues or service failures. To prevent this, inference environments rely on responsive cooling systems with built-in redundancy, continuous monitoring, and rapid failover capabilities..
Cooling Strategies:
Training environments routinely push racks past 100–160 kW, with next-generation accelerators expected to exceed 300 kW. At these intensities, liquid cooling becomes essential for consistent, high-capacity heat removal. Training clusters therefore rely on engineered liquid loops that deliver precise temperature control and reliable performance under continuous heavy load.
Because inference clusters often operate at lower power levels, air or hybrid cooling has traditionally been sufficient. However, this is changing as inference workloads scale and GPU performance increases. While inference densities may not match trainings’, the upward trend makes flexible, liquid-ready cooling infrastructure increasingly important.
Cooling Economics:
AI training’s primary goal is producing accurate, high-quality models — a task that becomes increasingly demanding as companies release new AI models at a rapid pace. When this happens, the energy spent training earlier models is effectively discarded, driving up overall demand for power and cooling to train the next iteration. This mindset pushes cost considerations to the background, with operators willing to accept high energy and cooling bills for optimizing model qualities.
Inference is far more cost-sensitive, placing a strong emphasis on efficiency, cost-per-query, and measurable return on investment. With cooling being a major driver of operating costs, operators prioritize energy-efficient systems to lower expenses and closely track metrics like PCE (Power Compute Effectiveness) and ROIP (Return on Invested Power) to ensure that every kilowatt delivers maximum compute performance and economic value.
By linking energy use directly to AI performance, PCE and ROIP provide a clearer picture of how cooling, infrastructure, and hardware choices impact the real economics of inference at scale.
Cooling Comparison: AI Training vs. Inference
| Category | AI Training | AI Inference |
|---|---|---|
| Deployment Environment | Centralized hyperscale and colocation sites built for high-power compute. | Modular, regional, and edge sites with varied space and power limits. |
| Demand Pattern | Sustained, dense, predictable heat output. | Bursty, unpredictable heat driven by real-time demand. |
| Uptime Requirements | Can tolerate longer recovery windows. | Requires continuous uptime. |
| Cooling Strategies | Liquid cooling (direct-to-chip, CDUs). | Air or hybrid cooling. |
| Cooling Economics | Prioritizes model quality over operational cost. | Highly cost-sensitive; efficiency tracked via PCE and ROIP. |
Make Cooling the Enabler of Your AI Strategy
Training and inference may be two sides of the AI lifecycle, but they shape cooling in dramatically different ways. Designing around those differences is essential for performance, efficiency, and growth, positioning cooling as either the bottleneck or the enabler of AI expansion.
AIRSYS helps operators bridge this gap with AI-ready cooling solutions engineered for both the extreme loads of AI training and the dynamic, distributed nature of inference, ensuring your infrastructure can grow as fast as your AI strategy. Explore our cooling solutions for HPC environments and cooling solutions for edge infrastructure to find the right fit for your AI workloads.



{kind=link}